%201-1.webp?width=148&height=74&name=our%20work%20(2)%201-1.webp)





Language plays a fundamental role in human communication, and in today's online era of ever-increasing data, it is inevitable to create tools to analyze, comprehend, and communicate coherently.
This is where LLM comes in the big picture.
A Large Language Model is an ML model that can do various Natural Language Processing tasks, from creating content to translating text from one language to another. The term "large" characterizes the number of parameters the language model can change during its learning period, and surprisingly, successful LLMs have billions of parameters.
Key Takeaways:
- Comprehend everything about LLMs and their present state of the art.
- Understand different types of LLMs and evaluate if it is a - fad or wham.
- Discover the best ways to train LLMs from scratch and analyze them.
So, let's talk about it!
What Are Large Language Models (LLMs)?
In layman's terms, the "Large Language Model" is a trained deep-learning model that understands and produces content in a human-like manner. Behind the big stage, a large transformer model does wonders.
A Large Language Model is a deep-learning algorithm that does several Natural Language Processing tasks.
Furthermore, large learning models must be pre-trained and then fine-tuned to teach human language to solve text classification, text generation challenges, question answers, and document summarization.
The potential of Large Language Models to solve diverse problems finds applications in fields ranging from finance and healthcare to entertainment., where these LLM models serve an array of NLP applications, like AI assistants, chatbots, translation, and so on.
Large Language Models consist of untold parameters, akin to memories the model gathers as it learns during training. You can consider these parameters as the model's knowledge bank.
What is Large Language Model Development?
While understanding what an LLM is important, businesses today are more focused on large language model development. It is the complete process of designing, training, optimizing, and deploying language models for real-world applications.
Integrating HITL workflows into these stages helps maintain high accuracy by leveraging human expertise to validate model responses in nuanced scenarios.
LLM development goes beyond simply using a pre-built API. It involves building customized AI systems tailored to domain-specific data. Additionally, the solutions must meet performance requirements, security constraints, and scalability requirements.
Large language model development typically includes:
- Data strategy and governance planning
- Model architecture selection
- Pre-training or fine-tuning approach
- Infrastructure setup (GPU clusters, distributed training)
- Evaluation and benchmarking
- Deployment and continuous monitoring
Organizations investing in LLM development aim to build proprietary AI capabilities rather than rely entirely on third-party foundation models.
A Quick Recap of the Large Language Model Architecture
In the year 2017, everything changed.
Vaswani announced (I would prefer the legendary) paper "Attention is All You Need," which used a novel architecture that they termed as "Transformer."
Nowadays, the transformer model is the most common architecture of a large language model. The transformer model processes data by tokenizing the input and conducting mathematical equations to identify relationships between tokens. This allows the computing system to see the pattern a human would notice if given the same query.
Besides, transformer models work with self-attention mechanisms, which allows the model to learn faster than conventional extended short-term memory models. And self-attention allows the transformer model to encapsulate different parts of the sequence, or the complete sentence, to create predictions.
All in all, transformer models played a significant role in natural language processing. As companies started leveraging this revolutionary technology and developing LLM models of their own, businesses and tech professionals alike must comprehend how this technology works.
Understanding how these models handle natural language queries is especially crucial, enabling them to respond accurately to human questions and requests.
Must Read - Large Language Models Use Cases Across Various Industries
What are The Key Elements of Large Language Models?
Large Language Models are made of several neural network layers. These defined layers work in tandem to process the input text and create desirable content as output.
-
The Embedding Layer
This layer is a crucial element of Large Learning Models. The embedding layer takes the input, a sequence of words, and turns each word into a vector representation. This vector representation of the word captures the meaning of the word, along with its relationship with other words.
-
The Feedforward Layer
The Feedforward layer of an LLM is made of several entirely connected layers that transform the input embeddings. While doing this, these layers allow the model to extract higher-level abstractions - that is, to acknowledge the user's intent with the text input.
-
The Recurrent Layer
The recurrent layer allows the LLM to learn the dependencies and produce grammatically correct and semantically meaningful text.
-
The Attention Mechanism
The attention mechanism in the Large Language Model allows one to focus on a single element of the input text to validate its relevance to the task at hand. Plus, these layers enable the model to create the most precise outputs.
Types of Large Language Models
Often, Large Language Models are classified on the tasks they do:
- Autoregressive LLMs
- Transformer-Based LLMs
- Multilingual Models
- Hybrid Models
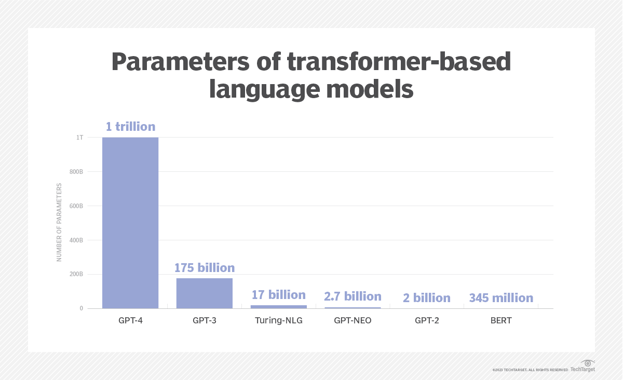
1.) Autoregressive LLMs (Predicting the next word)
The Large Learning Models are trained to suggest the following sequence of words in the input text. In simple terms, their sole task is to continue the text.

For instance, in the text "How are you?" the Large Learning Models might complete sentences like, "How are you doing?" or "How are you? I'm fine".
The Large Learning Models falling under this category are Transformers, LaMDA, XLNet, BERT, and GPT-3.
- GPT - 3 - GPT-3 is a revolutionary language model with the potential to deliver high-quality and human-like text according to the description provided. Besides, GPT-3 uses billions of parameters and techniques in creating human-like sentences.
- LaMDA - LaMDA is a factual language model trained to create different creative text patterns, like poems, code, scripts, musical pieces, emails, letters, etc., and answer your questions informally.
- XLNet - XLNet is an autoregressive language model that comprehends unsupervised representations of text sequences.
The only challenge circumscribing these LLMs is that it's incredible at completing the text instead of merely answering. Many times, we look forward to answers rather than completion.
Considering the above-discussed example, "How are you?" as an input, the Large Learning Model tries to complete the text with text like "doing?" or "I am fine." This portrays that a response can be either - a completion or an answer. This exactly defines why the dialogue-optimized LLMs came into existence.
Related Read: Top 15 Large Language Models in 2025
2.) Transformer-Based LLMs (Dialogue Optimized)
These types of LLMs reply with an answer instead of completing it. So, when provided the input "How are you?", these LLMs often reply with an answer like "I am doing fine." instead of completing the sentence.

The list of dialogue-optimized LLMs are ChatGPT, BERT, BARD, InstructorGPT, Falcon-40B-instruct, etc.
- BERT - BERT (Bidirectional Encoder Representation from Transformers) is a dynamic auto-regressive LLM that operates on deep neural work. Its primary focus is understanding the relationship between the words instead of focusing on one word's meaning.
3.) Multilingual Models
Multilingual models are trained on diverse language datasets and can process and produce text in different languages. They are helpful for tasks like cross-lingual information retrieval, multilingual bots, or machine translation.
- XLM- XLM is a cross-lingual language model created by Facebook.
4.) Hybrid Models
A hybrid model is an amalgam of different architectures to accomplish improved performance. For example, transformer-based architectures and Recurrent Neural Networks (RNN) are combined for sequential data processing.
- UniLM (Unified Language Model) is a hybrid Large Language Model that combines auto-regressive and sequence-to-sequence modeling approaches.
There's more. Especially if you want a definitive success, this is just unskippable.
Difference Between Generative AI and Large Language Models
Generative AI is a vast term; simply put, it's an umbrella that refers to Artificial Intelligence models that have the potential to create content. Moreover, Generative AI can create code, text, images, videos, music, and more. Some popular Generative AI tools are Midjourney, DALL-E, and ChatGPT.
Large language models are a type of generative AI that is trained on text and generates textual content. ChatGPT is an excerpt of Generative text AI.
All Large Language Models are Generative AI.
Now, if you are sitting on the fence, wondering where, what, and how to build and train LLM from scratch. Don't worry; we've got you covered.
How to Build a LLM: Step-by-Step Development Framework?
Building a large language model requires a structured engineering process. Whether you plan to build LLM systems from scratch or fine-tune an existing model, the development lifecycle follows a defined framework.
Step 1: Define Objectives
A clear objective prevents unnecessary computing expenses. Before starting LLM development, clearly define:
- What tasks should the model perform?
- Target industry or domain
- Expected accuracy and latency
- Regulatory or compliance constraints
Step 2: Identify Requirements for Building a Large Language Model
The requirements for building a large language model (LLM) span across multiple dimensions:
| Category | Key Requirements |
| Technical | GPUs (A100/H100), distributed training, large-scale storage, MLOps setup |
| Data | Curated text corpus, domain datasets, deduplication, governance compliance |
| Talent | ML engineers, NLP specialists, data engineers, DevOps support |
Understanding these requirements early helps optimize costs and timelines for large language model development.
Step 3: Data Collection and Preparation
High-quality data is the backbone of any successful LLM development initiative. This stage involves collecting large-scale datasets from reliable sources, filtering irrelevant or low-quality content, and removing noise or toxic material.
The data must then be tokenized and prepared with an appropriate vocabulary structure. Finally, structured input-output training pairs are created to ensure the model learns meaningful language patterns and relationships.
Step 4: Select Architecture
Architecture selection plays a critical role in determining model performance, scalability, and training complexity. Depending on the use case, organizations may choose decoder-only (autoregressive) models for text generation tasks. For instance, encoder-only models for understanding and classification tasks, encoder-decoder models for translation or summarization, or hybrid architectures that combine multiple approaches for flexibility and performance.
Step 5: Choose Development Approach
Selecting the right approach is critical when deciding how to create a LLM model efficiently. There are three major approaches to LLM development:
- Build from scratch – suitable for research-heavy or highly proprietary use cases
- Fine-tune existing foundation models – cost-effective and practical
- Use Retrieval-Augmented Generation (RAG) – integrates external knowledge for accuracy
6: Training and Optimization
The model training phase consumes the majority of compute resources in large language model development. It involves:
- Hyperparameter tuning
- Learning rate scheduling
- Regularization techniques
- Distributed parallel training
Step 7: Evaluation and Benchmarking
Evaluation ensures the model is production-ready. After training, evaluate the model using:
- Perplexity
- Task-specific benchmarks
- Human evaluation
- Bias and safety testing
Step 8: Deployment and Monitoring
Ongoing monitoring ensures performance stability and reduces hallucination risks. Once validated, deploy the LLM as:
- API services
- Containerized microservices
- Serverless endpoints
Next comes the model training using the preprocessed data collected.
How to Train LLMs from Scratch?
Training an LLM is different for different kinds of LLM. Supposedly, if you want to build a continuing text LLM, the approach will be entirely different from that of a dialogue-optimized LLM.
These 2 are crucial factors behind the performance of LLMs. So, let's discuss the different steps involved in training the LLMs.
-
Autoregressive LLMs
The training procedure of the LLMs that continue the text is termed as pertaining LLMs. These LLMs are trained in a self-supervised learning environment to predict the next word in the text.
Here's Each Step Involved in Training LLMs From Scratch:
Step 1: Collecting Dataset
The first and foremost step in training LLM is voluminous text data collection. After all, the dataset plays a crucial role in the performance of Large Learning Models.
Recently, "OpenChat," - the latest dialog-optimized large language model inspired by LLaMA-13B, achieved 105.7% of the ChatGPT score on the Vicuna GPT-4 evaluation.
The secret behind its success is high-quality data, which has been fine-tuned on ~6K data.
The data collected for training is gathered from the internet, primarily from social media, websites, platforms, academic papers, etc. All this corpus of data ensures the training data is as classified as possible, eventually portraying the improved general cross-domain knowledge for large-scale language models.
So, without any chance - Unleash the potential of LLMs with high-quality data!

Step 2: Dataset Preprocessing and Cleaning
Next comes the step of dataset preprocessing and cleaning.
As datasets are crawled from numerous web pages and different sources, the chances are high that the dataset might contain various yet subtle differences. So, it's crucial to eliminate these nuances and make a high-quality dataset for the model training.
Primarily, the actual steps depend on the dataset you are currently working on. Standard preprocessing measures include:
- Resolving spelling mistakes.
- Removing toxic/biased data.
- Turning emojis into their text equivalent.
- Data duplication.
The training data can be duplicated or nearly the same sentences since it's collected from numerous data sources solely from the internet. So, adhering to the practice of data deduplication is inescapable for two significant reasons:
- It helps the model not to memorize the same data every time.
- It helps evaluate LLMs better because the test and training data contain non-duplicated information.
Step 3: Preparing Data
Dataset preparation is cleaning, transforming, and organizing data to make it ideal for machine learning. It is an essential step in any machine learning project, as the quality of the dataset has a direct impact on the performance of the model.
During the pre-training phase, LLMs are trained to forecast the next token in the text. Therefore, input and output pairs are developed accordingly.
Step 4: Defining The Model Architecture
The next step is "defining the model architecture and training the LLM."
Presently, enormous LLMs are being developed. You can have an overview of all the LLMs at the Hugging Face Open LLM Leaderboard. Primarily, the researchers follow a defined process while creating LLMs.
Often, researchers start with an existing Large Language Model architecture like GPT-3 accompanied by actual hyperparameters of the model. Next, tweak the model architecture/ hyperparameters/ dataset to come up with a new LLM.
Step 5: Hyperparameter Tuning
There is no doubt that hyperparameter tuning is an expensive affair in terms of cost as well as time.
Don't worry! The ideal approach to get a handle on this is to use hyperparameters of present work; for instance, if you are working with GPT-3, use its hyperparameters with the corresponding architecture and then identify the optimal hyperparameters on a small scale, then interpolate them for the final mode.
This experiment includes any or all of the following:
- Positional embeddings
- Learning rate
- Weight initialization
- Optimizer
- Activation
- Loss function
- Number of layers, parameters, and attention heads
- Dense vs. sparse layers group out
Here are some proven practices you should follow for hyperparameters now:
- Learning Rate Scheduler - The proven approach is to minimize the learning rate as the training progresses, as it overcomes the local minima and improves the model stability.
- Regularization - Often, LLMs are prone to overfitting. Therefore, it's necessary to use techniques like dropout, batch normalization, and L1/L2 regularization to rescue the model from overfitting.
- Batch Size - Ideally, pick the large batch size that fits the GPU memory.
- Weight Initialization - The model convergence significantly depends on the weights initialized before training. After all, initializing the suitable weights leads to quicker convergence. But remember to use weight initialization only when you are defining your own LLM architecture.

-
Dialogue-Optimized LLMs
In the dialogue-optimized LLMs, the first and foremost step is the same as pre-training LLMs. Once pre-training is done, LLMs have the potential to complete the text.
Furthermore, to generate answers for a specific question, the LLMs are fine-tuned on a supervised dataset, including questions and answers. And by the end of this step, your LLM is all set to create solutions to the questions asked.
For example, ChatGPT is a dialogue-optimized LLM whose training is similar to the steps discussed above. The only difference is that it consists of an additional RLHF (Reinforcement Learning from Human Feedback) step aside from pre-training and supervised fine-tuning.
Once your LLM is trained, it's time to evaluate its performance. Let's see how!
How Do You Evaluate Large Learning Models?
The Large Language Model evaluation can't be subjective. Instead, it has to be a logical process to evaluate the performance of LLMs.
Considering the evaluation in scenarios of classification or regression challenges, comparing actual tables and predicted labels helps understand how well the model performs. Often, we look at the confusion matrix for this. But what in the case of LLM? They generate text.
Don't worry! There are two approaches to evaluate LLMs - Intrinsic and Extrinsic.
1.) Intrinsic Methods
Conventional language models were evaluated using intrinsic methods like bits per character, perplexity, BLUE score, etc. These metric parameters track the performance on the language aspect, i.e., how good the model is at predicting the next word.
- Perplexity: Perplexity is a measure of how well an LLM can predict the next word in a sequence. Lower perplexity indicates better performance.
- BLEU score: The BLEU score is a measure of how similar the text generated by an LLM is to a reference text. A higher BLEU score indicates better performance.
- Human evaluation: Human evaluation involves asking human judges to rate the quality of the text generated by an LLM. This can be achieved by using a variety of different assessments, like fluency, coherence, and relevance.
Moreover, it is equally important to note that no one-size-fits-all evaluation metric exists. Each metric has its own strengths and weaknesses. Therefore, it is essential to use a variety of different evaluation methods to get a wholesome picture of the LLM's performance.
Here are some additional considerations for evaluating LLMs:
- Dataset Biasing: LLMs are trained on large datasets of text and code. If these datasets are biased, then the LLM will also be limited. It is essential to be aware of the potential for bias in the dataset and to take steps to mitigate it.
- Safety: LLMs can be used to generate harmful content, such as hate speech and misinformation. It is essential to develop protection mechanisms to prevent LLMs from being used to create harmful content.
- Transparency: It is essential to be transparent about the way that LLMs are trained and evaluated. This will help build trust in LLMs and ensure they are used responsibly.
2.) Extrinsic Methods
With advancements in LLMs nowadays, extrinsic methods are becoming the top pick for evaluating LLMs' performance. The suggested approach to evaluating LLMs is to look at their performance in different tasks like reasoning, problem-solving, computer science, mathematical problems, competitive exams, etc.
EleutherAI launched a framework termed Language Model Evaluation Harness to compare and evaluate LLM's performance. HuggingFace integrated the evaluation framework to weigh open-source LLMs created by the community.
This framework evaluates LLMs across four different datasets. The final score is an accumulation of scores from each dataset. Here are the parameters:
- A12 Reasoning - This is a collection of science questions created for elementary school students.
- MMLU - This is a comprehensive test that evaluates the multitask precision of a text model. It sheaths 57 different tasks, including subjects like U.S. history, math, law, and much more.
- TruthfulQA - This test assesses a model's tendency to create accurate answers and skip generating false information commonly found online.
- HellaSwag - This is a test that challenges state-of-the-art models to make common-sense inferences that are easy for humans, with 95% precision.
Challenges in Large Language Model Development
Despite rapid advancements, LLM development presents several challenges. Understanding below risks helps organizations build safer and more scalable LLM systems:
High Compute Costs: Training large models requires massive GPU clusters and distributed systems.
Data Bias and Hallucination: Models trained on internet-scale data may inherit bias or generate inaccurate outputs.
Scalability and Latency: Deploying large models in production requires optimization to ensure low latency.
Regulatory and Security Risks: Enterprises must address compliance, data privacy, and IP protection when building LLMs.
Deploying the LLM
Finally, it's time to deploy the LLM in a production environment.
You can choose serverless technologies like AWS Lambda or Google Cloud Functions to deploy the model as a web service. Besides, you can use containerization technologies like Docker to package our model and its dependencies in a single container.
Enterprise Use Cases of Large Language Model Development
Custom large language model development allows enterprises to build AI systems aligned with their operational workflows and proprietary data. Organizations invest in LLM development to unlock measurable business value. Some common applications include:
- AI-powered customer support assistants
- Internal knowledge management bots
- Automated document analysis systems
- Code generation assistants
- Financial and legal document summarization
Concluding it All
Large Language Models, like ChatGPTs or Google's PaLM, have taken the world of artificial intelligence by storm. Still, most companies have yet to make any inroads to train these models and rely solely on a handful of tech giants as technology providers.
If you are also at square one and planning to go further, we will walk the extra mile for you.
Empower Your Business with LLM Development Services
Transforming Ideas into Intelligent Conversations - Expert Development for Large Language Models
At Signity, we've invested significantly in the infrastructure needed to train our own LLM from scratch. Our passion to dive deeper into the world of LLM makes us an epitome of innovation. Connect with our team for expert LLM development services to craft the next breakthrough together.
Buckle up and be ready to be the spearhead!

Mangesh Gothankar


Ashwani Sharma
Achin Verma
Frequently Asked Questions
Have a question in mind? We are here to answer. If you don’t see your question here, drop us a line at our contact page.
What hardware setup is required for training a large language model?
![]()
Training a large language model requires high-memory GPUs such as NVIDIA A100 or H100. Multi-GPU or distributed clusters are typically necessary for models above a few billion parameters.
You also need high-throughput storage and fast interconnects like NVLink or InfiniBand to reduce training bottlenecks.
How does distributed training work in LLM development?
![]()
Distributed training splits the model or data across multiple GPUs or nodes.
Data parallelism divides batches across GPUs, while model parallelism splits model layers. Large-scale LLM development often combines both approaches to handle memory and compute limits efficiently.
What is the difference between pre-training and fine-tuning in LLM development?
![]()
Pre-training trains a model on massive general-domain datasets using self-supervised objectives.
Fine-tuning adapts that pre-trained model to a specific domain using smaller labeled datasets. Besides, fine-tuning requires significantly less compute compared to full pre-training.
How do developers reduce memory usage during LLM training?
![]()
Memory usage can be reduced through gradient checkpointing, mixed-precision training (FP16 or BF16), and parameter-efficient fine-tuning methods.
Techniques such as LoRA and model sharding also help optimize GPU memory during large language model development.
How is model performance evaluated during LLM development?
![]()
Developers evaluate models using perplexity, task-specific benchmarks, and domain test datasets.
Human evaluation may also be used for quality validation. Since continuous monitoring is required after deployment to track drift and hallucination patterns.







.jpg?width=352&name=Top%20Large%20Language%20Models%20(LLMs).jpg)