%201-1.webp?width=148&height=74&name=our%20work%20(2)%201-1.webp)





Not long ago, picking an LLM for your business came down to maybe two or three options. You evaluated them, picked one, and moved on. That era is gone.
In 2026, the market looks completely different. New models keep coming every alternate month or so, each claiming to be faster, smarter, or cheaper than the last. For a business actually trying to build something with AI, this creates plenty of choices, creating a real problem. A model that tops a benchmark might still fall apart under your specific workload, latency needs, or your budget.
This is where LLM leaderboards come in. The better leaderboards today go far beyond accuracy scores; they compare models across reasoning depth, coding ability, tool use, multimodal tasks, context window handling, and real-world enterprise performance. For anyone making a serious AI investment, they've become an essential part of the due diligence process.
In this guide, we've pulled together the LLM leaderboards that actually matter for businesses evaluating models in 2026. And if you're planning a custom AI deployment, partnering with AI consulting services specialists can take a lot of the guesswork out of model selection, integration, and long-term strategy.
 Generate
Key Takeaways
Generate
Key Takeaways
- LLM leaderboards simplify model selection by offering benchmark-based comparisons of top-performing large language models across various use cases.
- Popular leaderboards like LMSYS, Hugging Face, and MTEB evaluate LLMs on diverse tasks like conversation, coding, and function calling.
- Each leaderboard focuses on different metrics such as accuracy, reasoning, speed, cost-efficiency, and real-world applicability, helping align model choices with business needs.
- While leaderboards guide model evaluation, implementation success depends on having the right expertise to customize and deploy LLMs effectively for your specific goals.
Top 7 Useful LLM Leaderboards for Large Language Model Selection
LLM leaderboards rank language models based on different benchmarks. They help track various language models and compare their performance. These leaderboards are particularly useful for deciding which models to use.
1. LMSYS Chatbot Arena Leaderboard
The platform started as LMSYS Chatbot Arena, then became LMArena, and by early 2026, it rebranded again to simply Arena.
The LMSYS Chatbot Arena leaderboard evaluates chat models and chat-based interfaces in conversational AI, emphasizing the importance of chat functionality for user interaction and engagement. It measures how well they manage complex and subtle conversations. This helps developers improve human-computer interaction using natural language processing.

The chatbot arena uses a detailed assessment system that combines human preference votes and Elo ranking method to evaluate large language models.
It uses a “blind” side-by-side comparison. Users submit prompts and vote for the better response from two randomly selected and anonymous models. The system uses votes to create Elo ratings, which rank the models.
The LMSYS Chatbot Arena leaderboard combines the following to provide a comprehensive evaluation:
1. Human Preference: The Chatbot Arena Elo rating system uses real-world user feedback and preferences for conversational tasks.
2. Automated Evaluation: Benchmarks such as AAI and MMLU-Pro provide a clear and comprehensive evaluation of knowledge and abilities in various domains.
Key Benchmarks for LLM Evaluation
Blind Testing: The blind nature of the comparisons reduces bias and enables a more objective evaluation of the models' capabilities.
Elo Rating System: The collected votes are used to calculate Elo ratings for each model. This system assigns a score to each LLM based on user votes in pairwise comparisons.
Dynamic Ranking: The leaderboard ranks models based on pairwise comparisons. Rankings can change as new models are added and more votes are cast.
Focus on User Preference: The LMSYS Arena primarily focuses on evaluating LLMs based on overall user preference. This means it also emphasizes human judgment.
Purpose and benefits of LMSYS Chatbot Arena Leaderboard
The LMSYS Chatbot Arena Leaderboard has several goals and advantages.
-
LMSYS leaderboard offers a clear and ongoing assessment of language models (LLMs) in conversations
-
Arena allows for comparisons between the performance of different LLMs.
-
It helps researchers and developers identify trends and areas for improvement in LLMs.
-
The Arena leaderboard helps businesses select the right LLMs for their specific needs.
2. Hugging Face Open LLM Leaderboard
The Hugging Face open LLM leaderboard enhances transparency and fosters open collaboration in language model evaluation. It supports a vast range of tasks and datasets, while also encouraging contributions from developers. Users can add new models, report errors, or supplement information to the leaderboard, thereby enhancing the quality and accuracy of the data. This scenario promotes diversity in model entry and continuous improvement in benchmarking methods.
This makes it vital for organizations that are exploring cost-effective open-source alternatives to proprietary models.
Hugging Face Evaluation Benchmarks
Hugging Face open-source LLM leaderboard uses seven widely accepted benchmarks for assessing LLMs.
- The AI2 Reasoning Challenge (ARC) tests the language model's ability to answer grade-school science questions that require both specific knowledge and reasoning skills.
- HellaSwag evaluates the commonsense understanding and inference of situations that require models to choose the most plausible ending to a given scenario.
- Massive Multitask Language Understanding (MMLU) is a comprehensive benchmark that covers 57 tasks across multiple domains, including mathematics, law, computer science, and more.
- TruthfulQA measures the model's ability to provide truthful answers and resist generating misinformation.
- IFEval challenges the models to respond to prompts containing specific instructions.
- Winogrande evaluates commonsense reasoning by requiring models to detect the antecedents of pronouns in ambiguous sentences accurately.
- Grade School Math 8K (GSM8K) assesses the model's ability to understand, reason about, and solve multi-step problems.
Why It Still Matters in 2026
As businesses increasingly deploy private and domain-specific AI systems, open-source models have become central to enterprise AI strategy. The Hugging Face leaderboard helps compare:
-
Model reasoning capability
-
Fine-tuning readiness
-
Deployment flexibility
-
Inference efficiency
-
Cost-to-performance ratio
Key Features of Hugging Face LLM Leaderboard
-
Transparency through open-source access
-
A comprehensive set of performance metrics
-
Regular updates that reflect the latest advancements in model development
Also Read: Top 15 Large Language Models in 2026
3. Vellum AI LLM Leaderboard
The Vellum AI LLM leaderboard has quietly become one of the more trusted references for teams actually trying to deploy foundation models in production. What sets it apart isn't just the models it covers, it's the benchmarks it uses to evaluate them.
Instead of leaning on tests that the models have essentially been trained to ace, Vellum uses newer, harder evaluation sets that push models in ways that matter for enterprise work:
- GPQA Diamond — tests deep scientific reasoning, not surface recall
- AIME 2025 — rigorous mathematical problem-solving
- SWE-Bench — real agentic coding tasks, not toy examples
- ARC-AGI 2 — abstract and visual reasoning under novel conditions
- Humanity's Last Exam — broad advanced reasoning across disciplines
- MMMLU — multilingual understanding across dozens of languages
These aren't arbitrary choices. Each one reflects a type of cognitive work that enterprise AI systems are increasingly being asked to do, whether that's debugging a codebase, processing multilingual inputs, or reasoning through complex multi-step decisions.
Why this matters for businesses in 2026
The highest benchmark score doesn't automatically mean the best model for your use case. A model that dominates on GPQA might be overkill, or underperform, when you're building a customer-facing copilot or an internal automation workflow. What you actually need is visibility into how a model behaves under the conditions your product creates.
Vellum's leaderboard gives you a layered view of that, covering reasoning quality, coding reliability, agent workflow consistency, context handling, and cost-to-performance ratios in a single place. That kind of side-by-side comparison saves teams weeks of internal testing just to narrow down candidates.
Of course, benchmark comparisons only get you so far. The real work, choosing the right architecture, setting up deployment correctly, deciding whether fine-tuning is worth it for your use case, starts after you've picked your shortlist. That's where working with an experienced partner tends to pay off, especially for teams without a dedicated ML infrastructure team in-house.
4. Berkeley Function-Calling Leaderboard
The Berkeley Function Calling Leaderboard (BFCL) is a benchmark that evaluates and compares the ability of large language models to perform function calling. This capability allows LLMs to interact with the external world, automate tasks, fetch real-time information, and integrate with APIs and services. Cloud providers like Amazon offer platforms for deploying and optimizing function-calling models, supporting integration with various APIs and services.
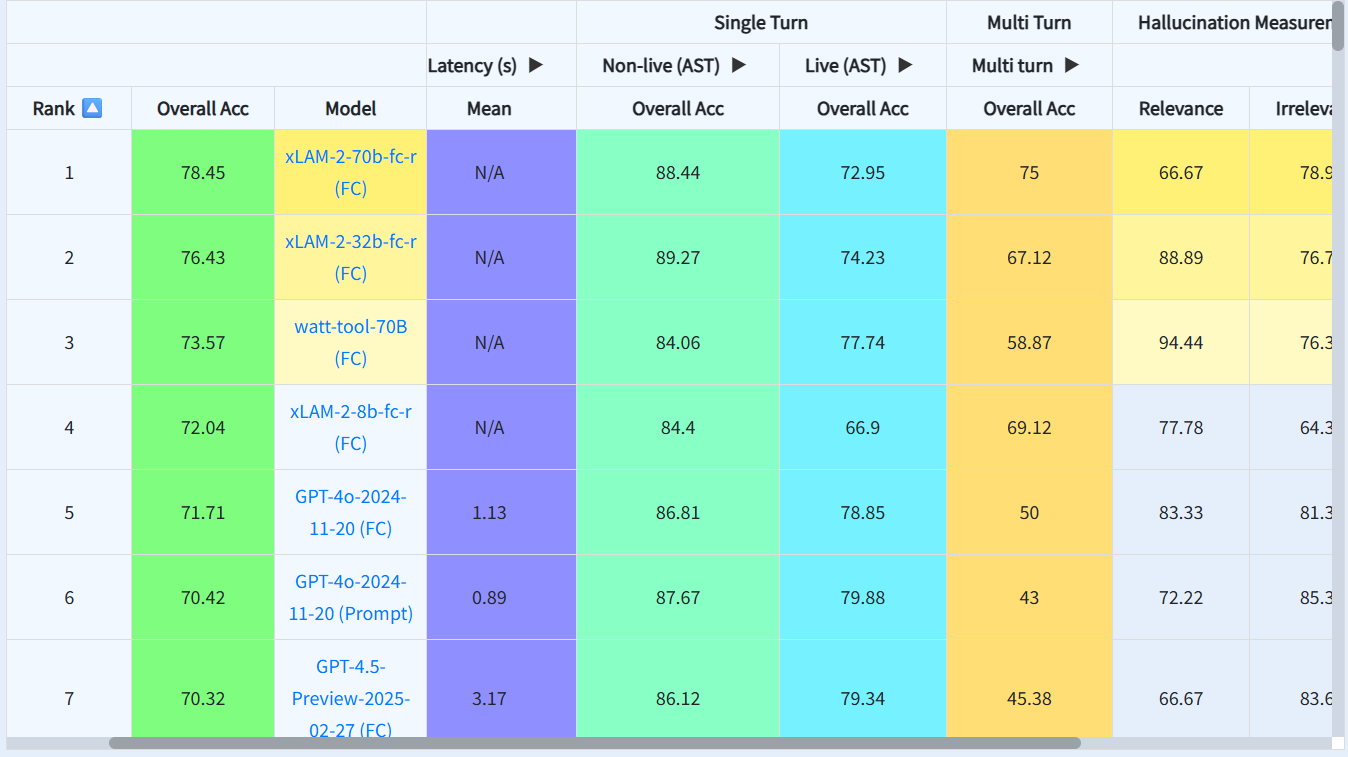
To provide a comprehensive and realistic evaluation of LLMs’ function-calling capabilities across a variety of scenarios. BFCL uses a novel Abstract Syntax Tree (AST) substring matching technique to assess the correctness of function calls generated by LLMs. The leaderboard also complements it with execution-based evaluation where feasible.
BFCL is a well-known benchmark because it includes a variety of tasks and real-world data. It focuses on important features like multi-turn interactions and relevance detection, which many other benchmarks often ignore.
Evaluation Benchmarks of BFCL
-
Single-turn focuses on scenarios involving a single function call.
-
Crowd-Sourced includes 2,251 real-world function-calling examples contributed by the community, showcasing practical use cases.
-
Multi-Turn evaluates the LLM's ability to maintain context and make dynamic decisions during conversations that involve multiple function calls.
-
It features eight API suites and 1,000 queries to test sustained context management and decision-making skills.
-
Agentic evaluates the LLM's ability to act as an AI agent.
5. SWE-bench Leaderboard
The SWE-bench leaderboard has become one of the most important coding-focused evaluation frameworks in 2026. It measures how effectively large language models solve real software engineering tasks using issues from public code repositories.
Unlike older coding benchmarks that focus on isolated code snippets, SWE-bench evaluates models on practical software development challenges. This includes understanding existing codebases, fixing bugs, generating patches, and resolving GitHub issues in real-world environments.
How SWE-bench Evaluates Models
SWE-bench tests models against real engineering workflows, making it highly relevant for businesses building AI-powered developer tools.
It evaluates:
- issue resolution across real repositories
- code generation for production tasks
- bug fixing accuracy
- repository-level reasoning
- multi-step software tasks
- test execution success
- patch validation
Many organizations also compare results alongside LiveCodeBench to assess performance on fresh coding tasks and benchmark recency.
Why It Matters in 2026
As coding assistants become a major business use case, software engineering performance has become a critical part of modern LLM leaderboard.
SWE-bench helps companies evaluate how models perform in practical engineering scenarios rather than controlled benchmark prompts. This makes it especially useful for businesses deploying:
- AI coding assistants
- internal developer copilots
- code review tools
- software automation workflows
- engineering support agents
6. Massive Text Embedding Benchmark (Mteb) Leaderboard
The Massive Text Embedding Benchmark (MTEB) leaderboard evaluates and compares the performance of text embedding models. It is hosted on Hugging Face and provides a standardized way to assess these models across a diverse range of tasks and languages.
As retrieval-augmented generation (RAG) becomes standard across business AI applications, embedding quality has become a critical factor in overall system performance. This makes MTEB an important part of any modern LLM leaderboard strategy. It is publicly accessible on GitHub and the Hugging Face platform, promoting transparency and collaboration.
Some of the top-performing models on the Massive Text Embedding Benchmark leaderboard in 2026 include Gemini Embedding 001, NV-Embed-v2, and Qwen3-Embedding-8B. These models lead across retrieval, semantic search, and multilingual embedding tasks, making them strong choices for modern RAG and enterprise search systems.
Evaluation Benchmarks of MTEB Leaderboard
MTEB evaluates models across eight distinct embedding tasks. Each one with private datasets and varying languages:
-
Bitext mining identifies matching sentences in two different languages.
-
Classification categorizes texts using embeddings and a logistic regression classifier.
-
Clustering groups similar texts together using mini-batch k-means scoring with V-measure.
-
Pair classification determines if two texts are similar.
-
Reranking is ranking a list of relevant and irrelevant texts based on a query.
-
Retrieval is about relevant documents for a given query.
-
Semantic Textual Similarity (STS) measures the similarity between sentence pairs.
-
Summarization evaluates machine-generated summaries against human-written ones using Spearman correlation based on cosine similarity.
Why It Matters in 2026
Enterprise AI systems increasingly rely on vector search for:
- document retrieval
- knowledge assistants
- semantic search
- recommendation systems
- internal enterprise search
- customer support automation
MTEB helps businesses compare which embedding models perform best for these use cases, making it an essential benchmark beyond traditional LLM rankings.
7. Artificial Analysis LLM Performance Leaderboard
The Artificial Analysis LLM Performance Leaderboard provides a comprehensive evaluation of large language models (LLMs) and their API providers. It differentiates itself by offering a holistic assessment that considers model quality and performance metrics like speed, latency, and pricing, alongside context window size.
The image below compares and ranks the performance of over 100 AI models (LLMs) across key metrics.

Artificial Analysis LLM Performance Leaderboard Evaluation Benchmarks
-
Quality is evaluated using a simple index that combines scores from benchmarks like MMLU, MT-Bench, and HumanEval.
-
Pricing measures the cost of using the models, including per-token input and output pricing, as well as a blended price calculation assuming a 3:1 input-to-output ratio.
-
Speed via Throughput represents the rate at which the models generate tokens. It is measured in tokens per second (TPS).
-
Speed via Latency measures the time to first token (TTFT), or how long it takes for the model to generate the first token of a response.
-
Context window is the maximum number of tokens an LLM can process at once.
Key Metrics LLM LeaderBoard Use to Evaluate LLMs
LLM leaderboards use various evaluation metrics to rank language models based on important criteria. Let’s look at the most common standards used for these rankings.
Accuracy and Performance
Models are evaluated on benchmarks such as classification, sentiment analysis, and summarization. These evaluate their accuracy in handling various language tasks.
Hallucination and Reliability
Model reliability is now a major enterprise metric. Benchmarks measure factual accuracy, consistency, and resistance to generating misleading or incorrect information.
Generative Capabilities
Text coherence, creativity, and relevance are evaluated through generative AI tasks. This involves creating well-structured and engaging responses that are contextually appropriate. Generative strength reflects the ability to produce compelling, human-like text beyond just factual accuracy.
Reasoning and Problem-Solving
LLM leaderboards evaluate models' problem-solving abilities through logical and mathematical reasoning benchmarks.
Multimodal Capabilities
The LLM leaderboards evaluate the growing capabilities of AI systems. So this has resulted in competitions involving models that can associate text with images, audio, and other forms of media.
Domain-Specific Performance
Industry-focused exams assess the performance of language models (LLMs) in specific fields, such as healthcare and finance. These tests check how effectively the model understands specialized language and uses reasoning relevant to those areas.
Latency and Speed
Accurate responses are vital for chatbots and virtual assistants. A model that provides precise answers but has slow response times can be frustrating. Low-latency responses are essential in high-demand situations where every millisecond counts.
F1 Score
The F1-score is a metric used to evaluate the performance of language models in classification and information retrieval tasks. It combines two important measures: precision and recall.
Here,
-
Precision indicates the proportion of predicted positive results that are actually correct. It tells us the percentage of relevant items among those selected.
-
Recall shows the proportion of true positive results to all actual positive cases. It indicates the number of relevant items selected.
Bilingual Evaluation Understudy (BLEU) Score
The BLEU score measures how good a machine-translated text is by comparing it to human translations. It checks how similar the machine-generated text is to reference texts by looking at the consistency of phrases and the overall structure.
The BLEU score is calculated using this formula:
-
The weight for the n-gram accuracy score is called w_n. We usually set the weights to 1 divided by n, where n is the number of different n-gram sizes we use.
-
p_n is the precision rating for a specific size of n-gram.
Bottom Line
While these LLM leaderboards are invaluable for measuring the success and choosing the right large language models, it is just the top page view that requires addressing.
Whether you’re building enterprise copilots, intelligent assistants, RAG systems, or custom AI applications, selecting the right LLM is easier when paired with the right implementation partner.
There is a huge part waiting on the other side that many businesses may struggle with. And that is finding the right expertise to implement it. That is why we are here to make it easier for you.
We have proven years of experience in developing custom solutions. Our expertise allows us to create the perfect blend of skills needed for your needs. We are here to deliver the best advanced LLM development services and advanced solutions that are right for your business. Get in touch today.

Mangesh Gothankar


Ashwani Sharma
Achin Verma
Frequently Asked Questions
Have a question in mind? We are here to answer. If you don’t see your question here, drop us a line at our contact page.
How often do LLM leaderboards change?
![]()
Can a lower-ranked LLM still be the better choice for my business?
![]()
Why do some models ace benchmarks but underperform in real applications?
![]()
Should I pick an open-source or proprietary model based on leaderboard scores?
![]()






.png?width=352&name=Role%20of%20AI%20in%20Software%20Development%20(4).png)