%201-1.webp?width=148&height=74&name=our%20work%20(2)%201-1.webp)





Enterprises running AI at scale always hit the same wall, and that is the bill.
Suppose developers work on a project that costs a few hundred dollars per month and suddenly doubles, and the invoice is making a hole in the pocket. The instinct is to blame the model. However, the real issue is that every query, no matter how trivial it is, goes to the same high-powered LLM. When a customer asks, “What exactly are your business hours?" it is routed to the same model that handles complex contract analysis. Basically, it means a senior resource is being utilized to answer front desk queries.
This problem, however, can be solved by LLM routing.
LLM routing adds an intelligent layer that helps decide which model should handle which request. It does not lock the application into a single model. So simple queries go to smaller and cost-effective models, and complex queries go to more capable ones. Ultimately, it results in an architecture that uses every model where it actually earns its cost.
Independent benchmarks back this up: peer-reviewed Route LLM research found that intelligent routing can cut costs by up to 85% while retaining 95% of flagship-model quality.
For businesses that actually want ot control AI spend, understanding how LLM routing works is no longer optional; rather, it's the core infrastructure. Here is a guide that breaks down what LLM routing is, how a multi-LLM architecture is built, and other routing strategies that businesses can rely on.
 Generate
Key Takeaways
Generate
Key Takeaways
- LLM routing directs queries to the best-fit model based on complexity, cost, and task type.
- A multi-LLM routing architecture typically blends proprietary and open-source models for capability and cost flexibility.
- Enterprises using model routing report cost reductions in the 40-85% range, depending on traffic mix and model pairing.
- Routing isn't plug-and-play; it requires ongoing monitoring to stay effective at scale.
What Is LLM Routing?
It is the practice of directing the incoming query to a suitable large language model from a pool of models available. It does not send every query to one fixed LLM.
Basically, it works as a mediator that sits between your application and model. Whenever there is an incoming request, it gets evaluated against a set of rules, then sent to the model that can handle it well, based on cost and speed. The application does not talk to Claude or other generative AI apps; it talks to the router, and it makes the decision.
A true model router makes an active decision on every request based on what the specific request actually needs. Suppose a basic LLM router sends a quick FAQ or simple customer query to a low-cost model, and a difficult query to look for multi-step legal reasoning, and more goes to another model that is built for complexity.
The Hidden Cost of a One-Model Approach
The cost problem rarely comes from the flagship use case that the board approved. It comes from everything built on top of it, like support ticket tagging, document summaries, and FAQ chatbots. All of these tasks are quietly routed through the same expensive model handling. This is the hardest issue companies face because that’s the only model wired in.
This is where enterprise LLM cost optimization stops being optional. A high-capability model charges by the token whether the task is "summarize this contract" or "what's your refund policy." At enterprise scale, that inefficiency compounds fast.
This is the gap LLM routing closes. The moment you route LLM traffic across multiple models instead of defaulting to one, you're fixing a structural cost problem, not micro-optimizing one.
How LLM Routing Works
LLM routing follows a simple sequence of tasks. There is a query that comes in, it gets evaluated, and is sent to the model that can handle it. The complexity is how the evaluation happens. Here is how the LLM routing works.
Query complexity
Is this a simple lookup or a multi-step reasoning task? Short factual questions and basic classification tasks don't need a frontier model's reasoning power. So here the router evaluates the user prompt with prompt engineering, looks for intent and context.
Task type
Summarization, code generation, translation, and open-ended reasoning often perform differently across LLM and foundation models. A router can match the task to the model proven best at it. The prompt gets paired with the best-fit model based on rules like cost and response speed.
Latency requirements
Some use cases, like live chats and voice assistants, need a fast response over a perfect one. Other complex tasks, like legal reporting and financial tasks, can tolerate a few extra seconds for better accuracy.
Cost threshold
Routers can be configured to stay within a budget per request type, automatically downgrading to a cheaper model when a task doesn't justify premium pricing.
Model capability and confidence
Some of the routing systems track how a model has performed historically on similar queries, while using that history to inform future decisions.
Multi-LLM Routing Architecture: What It Looks Like in Practice
Multi-LLM routing architecture comes down to different moving parts that work together. Each handles one piece of information or puzzle so that the other system does not have to think about it.
Orchestration Layer
This is the entry point, and it receives a request from the application and hands it off for processing. The application never talks to a model directly. Rather, it talks to the layer and gets a response. It does not have any idea which model actually did the work.
Routing Engine
The decision happens here. This is the same decision-maker who walked through earlier, weighing query complexity, cost, and task type before picking a model from the pool.
Model Pool
That pool is rarely made up of just one type of model. Enterprises usually mix a frontier model like GPT-4 for the hard reasoning tasks, a mid-tier model for everyday queries, and something open-source like Llama to soak up high-volume, low-complexity work such as tagging or basic summaries. There's a reason for the mix: proprietary models bring top-end capability, while open-source models bring the cost flexibility that makes scaling affordable.
Fallback Logic
None of this matters much if a model goes down mid-request. Suppose the model is not reachable and is unable to provide an accurate response; it reroutes the request to another backup and does not let the request fail. It's basically a minor detail that makes a difference between a system that works in demo and one that survives in production traffic.
Logging and Monitoring
This piece is less visible but arguably the most valuable long-term. Every routing decision, like which model got picked, how long it took, what it cost, and how well it performed, gets recorded somewhere. Without that data, routing rules get set once and never improve. With it, they get sharper every month.
Routing Strategies Enterprises Use
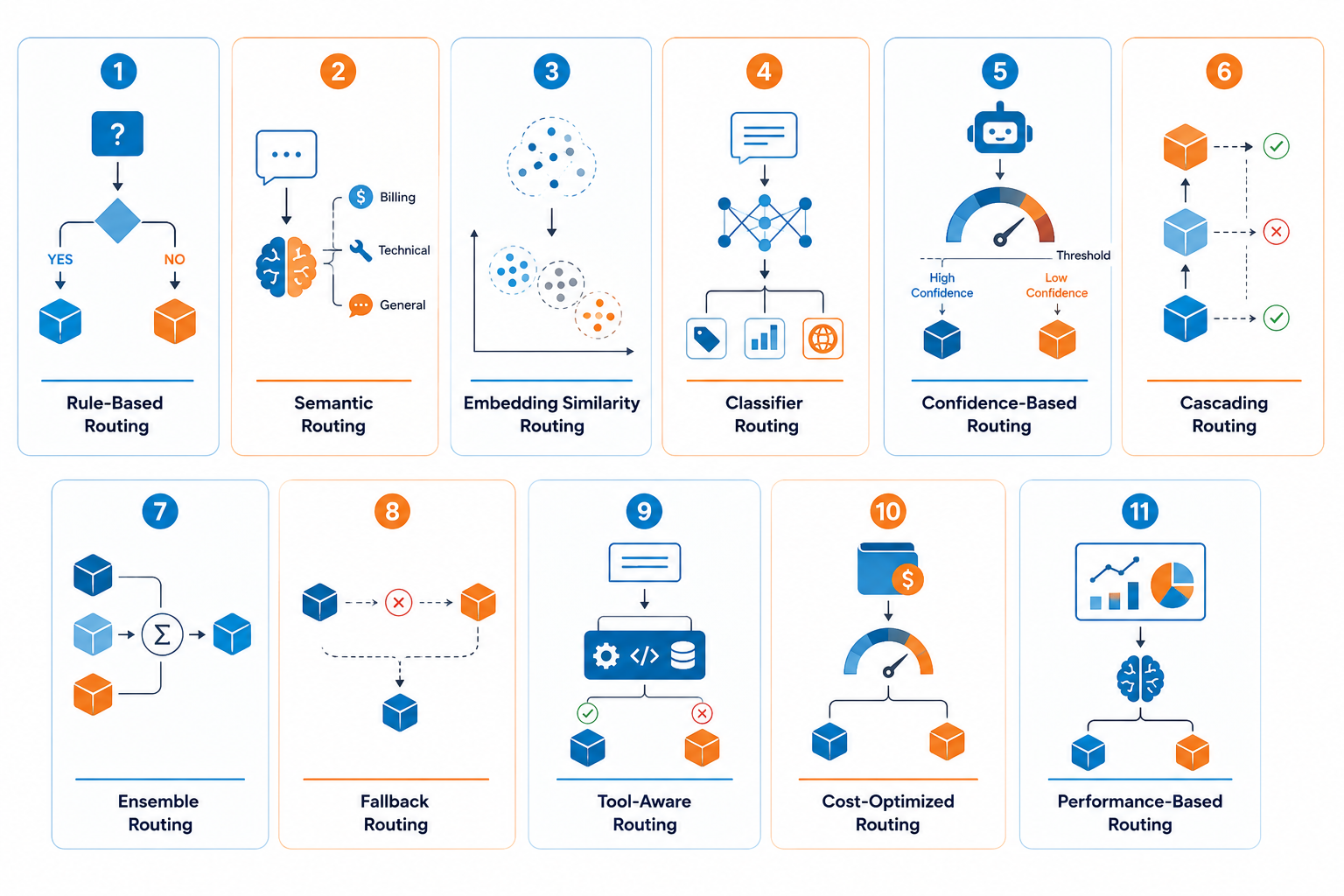
Every router does not make a decision in the same way. Most of the enterprise system relies on one or more strategies, which often blend them as per the use case.
Rule-Based Routing
This is one of the simplest approaches, as here a set of predefined conditions decides where a query goes. If a request matches a known FAQ pattern or falls under a certain length, it's sent to a lightweight model. Anything outside those rules defaults to a more capable one. It can be set up easily, and that makes it a common starting point.
Semantic Routing
Here, the router looks at what a query actually means rather than just matching surface-level patterns. A lightweight classifier model interprets the intent of whether it is a billing question, a technical issue, or a general inquiry and routes accordingly. This handles edge cases that rigid rules would miss.
Embedding Similarity Routing
This approach converts the incoming query into a vector embedding and compares it against embeddings of past queries. If the new query lands close to a cluster of queries, it gets routed there. It's faster and cheaper than running a full classifier model, typically adding only a few milliseconds of overhead, and works well when there's a healthy library of historical query data to compare against.
Classifier Routing
A small, purpose-trained model sits in front of the router and predicts which category a query belongs to, such as task type, difficulty level, or domain, before the router picks a model. Unlike rule-based routing, the classifier can generalize to phrasing it hasn't seen before. This is the approach behind several published routing benchmarks, where a trained classifier was able to send the majority of traffic to a budget model while keeping quality close to a flagship model's output.
Confidence-Based Routing
Here, a smaller or cheaper model attempts the query first, and the system checks how confident that model is in its own answer. If the confidence score clears a set threshold, the response is returned as-is. If it falls short, the query gets escalated to a more capable model. This keeps cost low for the bulk of queries a cheap model can handle confidently, while still catching the cases where it would have struggled.
Cascading Routing
This is a step-up approach where a query is first sent to the cheapest model in the pool. If that model's output fails a quality check, the same query cascades up to the next tier, and so on, until a response clears the bar or the top-tier model is reached. It's a practical middle ground between always defaulting to a frontier model and risking a low-quality answer from a cheap one.
Ensemble Routing
Instead of picking a single model, the router sends the same query to multiple models at once and combines their outputs, either by majority vote, weighted voting based on historical accuracy, or by having a separate model act as judge to select the best response. This trades extra cost and latency for higher reliability, and tends to get reserved for high-stakes queries where getting the answer wrong is costlier than running a few extra calls.==
Fallback Routing
This strategy isn't about picking the best model upfront; it's about what happens when the chosen model fails, times out, or returns a low-confidence result. The router automatically redirects the request to a backup model so the application doesn't see a dropped request. It overlaps with the fallback logic in the broader architecture, but as a routing strategy it can also be applied deliberately, for example, always keeping a cheaper backup ready behind a frontier model that has rate limits or occasional outages.
Tool-Aware Routing
Some queries need a model that can reliably call external tools, functions, or APIs, while others are pure text generation. Tool-aware routing checks whether a query requires function calling, retrieval, or other tool use, and routes only to models in the pool that support that capability well. This matters increasingly for agentic workflows, where sending a tool-calling query to a model that handles function calling poorly can break the entire workflow downstream.
Cost-Optimized Routing
This strategy sets a budget per request type and routes within it. Suppose a task can be easily handled by a cost-efficient model; by default, it will go there and keep the premium models safe for queries that need that capability level. Enterprises managing thousands of daily queries rely on this, since it directly ties routing decisions to spend.
Performance-Based Routing
Instead of fixed rules, this approach tracks how well each model has performed on similar queries in the past. It includes accuracy, latency, and user feedback, and uses that history to inform future routing. It's the most adaptive strategy, but also the one requiring the most ongoing monitoring to stay reliable.
Recommended Post: Streamlining Operations with LLM Development
Real Benefits: What Enterprises Actually Gain
The theory behind LLM routing is straightforward. What actually convinces enterprises to implement it is what shows up on the other side. It includes the budget, the response time, and more. Here are a few real benefits of LLM routing.
Cost reduction
It is usually the first number people look at, and it's often significant. Enterprises that move from a single-model setup to a routed architecture generally report cutting AI infrastructure costs, depending on how much of their traffic was simple, high-volume queries that never needed a frontier model in the first place. The savings scale with usage, so the more requests flowing through, the more a misallocated model costs, and the more a routed system saves by comparison.
Quality Stays Consistent
Routing doesn't mean settling for a worse model on harder tasks; it means matching task difficulty to model capability instead of either overpaying for a simple one. A well-tuned router sends each query to a model that's actually equipped to handle it, which means quality goes up on the tasks that matter, not down.
Improves Latency
Routing simple queries to lightweight models doesn't just save money; it gets answers back to users quicker, which matters a lot for live chat and customer-facing tools where speed is part of the experience.
Vendor Flexibility
A routing layer decouples the application from any single provider. If a better or cheaper model becomes available, or if a provider raises prices or has an outage, it can be added to the pool or swapped in without rebuilding the application from scratch.
And for regulated industries, routing opens the door to compliance and data residency control; sensitive queries can be routed to on-prem or private models, while general queries go to cloud-based ones, giving enterprises a way to meet data handling requirements.
Challenges and What to Watch Out For
No system that routes traffic across multiple models is "set and forget." Enterprises that get the most out of LLM routing are the ones that go in knowing what it takes to maintain it.
| Challenge | What It Actually Means |
| Routing logic maintenance | Rules drift out of sync as usage patterns shift and new models launch; they need regular review. |
| Evaluation drift | A model that performed well months ago may no longer be the best fit without ongoing re-evaluation. |
| Cold-start problems | New models or use cases start with little performance history, so early routing decisions rely on assumptions. |
| Misrouting sensitive tasks | Sending sensitive or regulated data to the wrong model can create real compliance risk. |
Conclusion
LLM routing isn't a future-state concept; it's already the difference between AI infrastructure that scales sustainably and one that scales into an unmanageable bill. Not every query deserves the same model, and model routing is what makes that distinction automatically instead of leaving it to a single expensive default.
Enterprises that route LLM traffic intelligently aren't just cutting costs; they're building systems flexible enough to adapt as the AI landscape keeps shifting. That's the real edge in any serious LLM routing enterprise setup.
At Signity, we help businesses design and implement exactly this kind of routing architecture, built around your models, and all within your budget. If you're ready to bring AI costs under control, leverage our LLM development services.
Frequently Asked Questions
Have a question in mind? We are here to answer. If you don’t see your question here, drop us a line at our contact page.
1. Does LLM routing add noticeable latency to a request?
![]()
2. Can LLM routing be implemented without rebuilding existing AI applications?
![]()
3. How do enterprises decide which models belong in the routing pool?
![]()
4. Is LLM routing only useful for enterprises with very high query volume?
![]()






-1.png?width=352&name=AI%20in%20Navigation%20%20(1)-1.png)